%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Video Synthesis
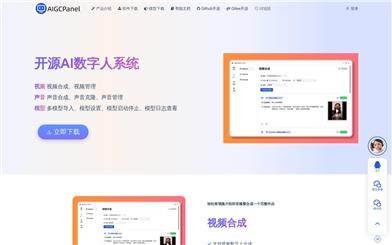
Aigcpanel Open Source AI Digital Human System
AIGCPanel is a user-friendly one-stop AI digital human system accessible even for beginners. It supports video synthesis, audio synthesis, and voice cloning, simplifying local model management with one-click import and use of AI models. Product background indicates that AIGCPanel aims to enhance the efficiency of digital human material management by integrating various AI functionalities while lowering technical barriers, making it easy for non-professionals to manage and use AI digital humans. The product is based on AGPL-3.0 open-source license and is completely free to use.
Digital Human
74.5K
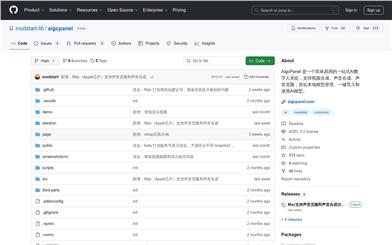
Aigcpanel
AigcPanel is a straightforward and user-friendly one-stop AI digital persona system, supporting video synthesis, sound synthesis, and voice cloning, while simplifying local model management and one-click model integration. Leveraging the latest in artificial intelligence technology, it provides users with efficient and convenient solutions for creating digital personas, making it particularly suitable for professionals and enterprises needing to produce video and audio content. AigcPanel holds a firm position in the digital persona creation field thanks to its ease of use, efficiency, and powerful capabilities.
Digital Human
87.2K
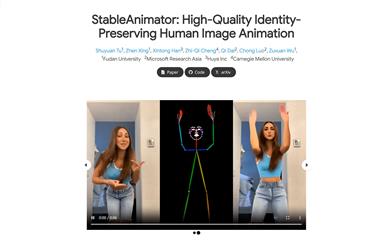
Stableanimator
StableAnimator is the first end-to-end identity-preserving video diffusion framework that synthesizes high-quality videos without the need for post-processing. This technology ensures identity consistency through conditional synthesis based on reference images and a series of poses. Its main advantage is that it does not rely on third-party tools, making it suitable for users who need high-quality portrait animations.
Video Production
68.2K

MIMO
MIMO is a versatile video synthesis model that can mimic any individual interacting with objects during complex motions. It synthesizes character videos with controllable attributes such as characters, actions, and scenes based on simple inputs provided by the user (e.g., reference images, pose sequences, scene videos, or images). MIMO achieves this by encoding 2D video into compact spatial codes and decomposing them into three spatial components (main subject, underlying scene, and floating occlusions). This method allows users to flexibly control spatial motion representation and create 3D perceptive synthesis, suitable for interactive real-world scenarios.
AI video generation
169.2K
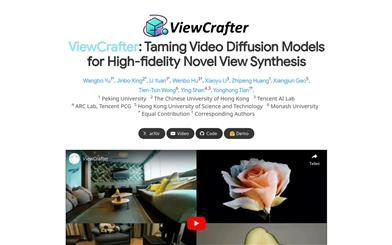
Viewcrafter
ViewCrafter is an innovative approach that leverages the generative capabilities of video diffusion models and the coarse 3D cues provided by point-based representations to synthesize high-fidelity new viewpoints of general scenes from single or sparse images. The method progressively expands the area covered by 3D cues and new viewpoints through iterative view synthesis strategies and camera trajectory planning algorithms, thereby increasing the generation range of new viewpoints. ViewCrafter can facilitate various applications, such as creating immersive experiences and real-time rendering by optimizing 3D-GS representations, as well as promoting imaginative content creation through scene-level text-to-3D generation.
AI image generation
59.6K
Fresh Picks
SF V
SF-V is a diffusion-based video generation model that optimizes a pre-trained model through adversarial training, achieving the capability of generating high-quality videos in a single step. This model significantly reduces the computational cost of the denoising process while maintaining the temporal and spatial dependencies of video data, paving the way for real-time video synthesis and editing.
AI video generation
56.0K
Fresh Picks
Align Your Steps
Align Your Steps is a method for optimizing the sampling time schedule of diffusion models (DMs). This approach utilizes stochastic calculus to find specific optimal sampling time schedules for different solvers, well-trained DMs, and datasets. It optimizes time discretization, i.e., sampling scheduling, by minimizing the KLUB term, thus improving the output quality within the same computation budget. This method performs exceptionally well in image, video, and 2D toy data synthesis benchmark tests, with optimized sampling schedules outperforming previously manually crafted schedules in almost all experiments.
AI Model
127.5K
Snap Video
Snap Video is a video-centric model that systematically addresses the challenges of motion fidelity, visual quality, and scalability in video generation by extending the EDM framework. Utilizing frame-level redundancy, the model proposes a scalable transformer architecture that represents the spatial and temporal dimensions as a highly compressed 1D latent vector. This allows for effective joint modeling of space and time, resulting in the synthesis of videos with strong temporal coherence and complex motion. This architecture enables the model to be efficiently trained to billions of parameters, achieving state-of-the-art results on multiple benchmarks.
AI video generation
200.9K
Boximator
Boximator is an intelligent video synthesis tool developed by Jiawei Wang, Yuchen Zhang, and others. It utilizes advanced deep learning techniques to generate rich and controllable video motion by adding text prompts and additional box constraints. Users can create unique video scenes through examples or custom text. Compared to other methods, Boximator utilizes supplementary box constraints from text prompts, providing more flexible motion control.
AI video generation
576.8K
Lumiere
Lumiere is a text-to-video diffusion model designed to synthesize videos that exhibit realistic, diverse, and coherent motion, addressing key challenges in video synthesis. We introduce a spatio-temporal U-Net architecture that enables the generation of an entire video's temporal duration in a single model pass. This contrasts with existing video models, which synthesize distant keyframes and then perform temporal super-resolution, a method that intrinsically makes global temporal consistency difficult to achieve. By deploying spatial and, importantly, temporal downsampling and upsampling, and leveraging a pre-trained text-to-image diffusion model, our model learns to directly generate full-frame rate, low-resolution videos at multiple spatio-temporal scales. We demonstrate state-of-the-art results in text-to-video generation and showcase that our design readily facilitates a variety of content creation tasks and video editing applications, including image-to-video, video repair, and style generation.
AI video generation
873.8K

Flowvid
FlowVid is an optical flow guided video synthesis model. By utilizing the spatial and temporal information of optical flow, it achieves temporal consistency between video frames. It seamlessly integrates with existing image synthesis models to enable various modification operations, including stylization, object swapping, and local editing. FlowVid boasts fast generation speed; a 4-second, 30FPS, 512×512 resolution video can be generated in just 1.5 minutes, outperforming CoDeF (3.1x), Rerender (7.2x), and TokenFlow (10.5x) respectively. In user evaluations, FlowVid achieved a quality score of 45.7%, significantly surpassing CoDeF (3.5%), Rerender (10.2%), and TokenFlow (40.4%).
AI Video Generation
81.7K

Charactr
gemelo is a generative AI platform that provides APIs for synthesizing voices, videos, and interactive virtual characters. With gemelo, you can generate realistic human voices, customize AI virtual characters, and create outstanding audio and video content for your business. gemelo's strength lies in its high-quality synthetic voices and videos, and you can achieve personalized customer interactions by training custom AI characters. Pricing is based on usage, see the official website for details.
AI Model
48.0K
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
42.8K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.7K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
42.2K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
43.1K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
42.2K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.8K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.4K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M